
Attention mechanism
이 전 챕터까지 RNN, GNU에 대해서 계속 학습해왔다. 이 모델들의 단점은 sentence가 길어지면 성능이 낮아지는 현상이 나타난다는 것이다. 그리고 이 현상을 너무 많은 정보가 하나의 노드로 들어가다 보니 bottle-neck현상이 일어난 것이 아닐까 보고 있다.
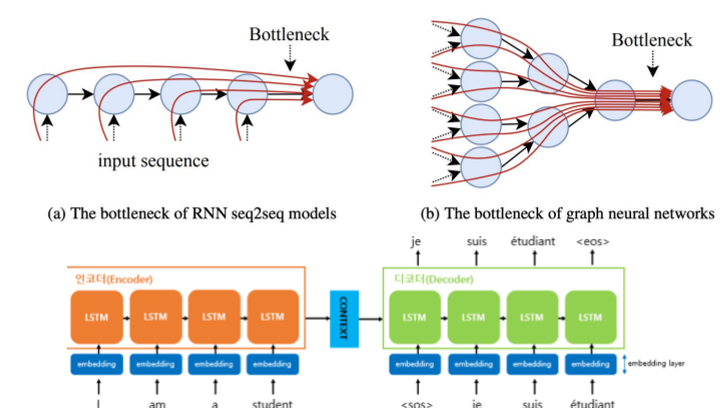
기존에 RNN, GNU 등의 성능이 좋지 않았던 이유는 결국 Encoder의 역할이 너무 많아서 Context vector가 모든 정보를 함축하지 못한다는 것이었다(LSTM, GRU를 써도 초기 정보가 희석된다). Context computing을 따로 하자. Encoder의 모든 feature를 사용하자. → Attention mechanism이 제시가 되었다.

Input과 output의 관계를 잘 고려하며 구조를 위와 같이 설계하게 된다. Attention Mechanism은 입력 시퀀스의 중요한 부분에 가중치를 부여하여 모델이 특정 부분에 집중할 수 있게 한다. 이를 통해 모델은 중요한 정보를 더 잘 학습할 수 있으며, 특히 긴 시퀀스를 처리할 때 유리하다.
Attention Mechanism 세부 과정
사실 단어와 단어 사이 관계 어디에 집중 하느냐에 따라 달려있다.
Step 1
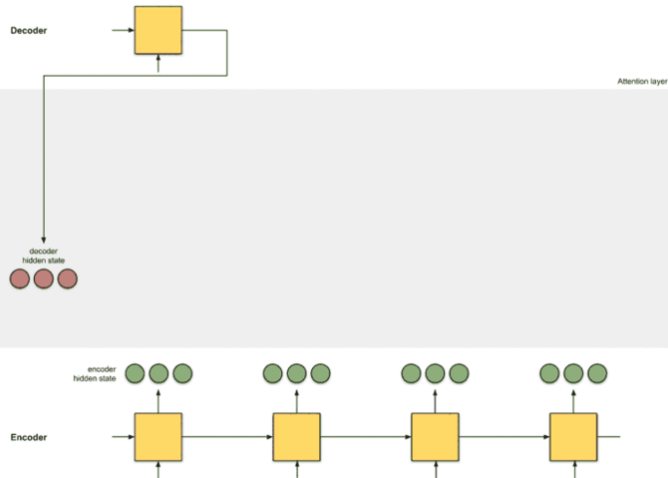
encoder RNN이 hidden state를 출력한다. encoder가 마지막으로 출력한 hidden vector가 decoder network의 initial state(h_0)가 될 것이다.
Step 2
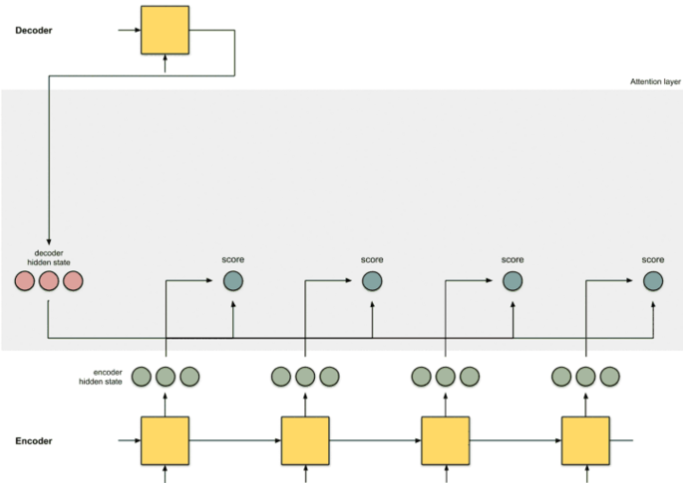
encoder RNN의 hidden vector와 decoder RNN의 hidden vector를 내적 하여 score를 구한다.
Step 3
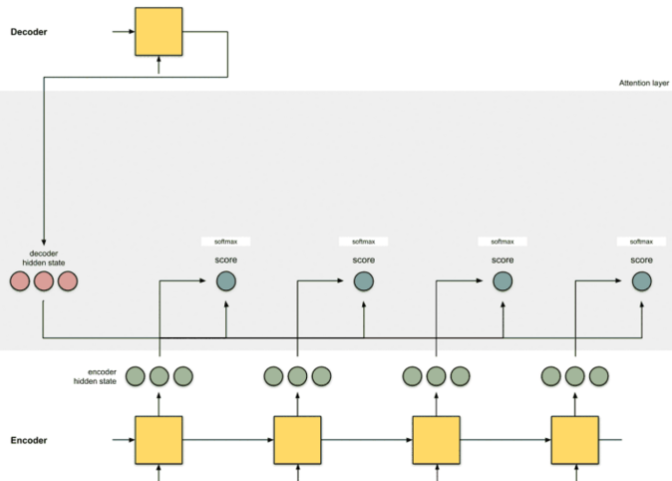
activation function으로 softmax를 사용하여 정규화하고 가중치(score)가 된다.
Step 4

다시 encoder의 hidden state와 가중치(score)를 가지고 multiplication 연산을 하고 이 결괏값들을 전부 더해서 가중합(addition)을 구한다.
Step 5

가중합 결과(context vector)는 디코더로 전달되어 다음 단어를 예측하는 데 사용된다. 이때, 디코더의 이전 출력과 새로운 콘텍스트 벡터를 결합하여 디코더의 다음 입력으로 사용된다.
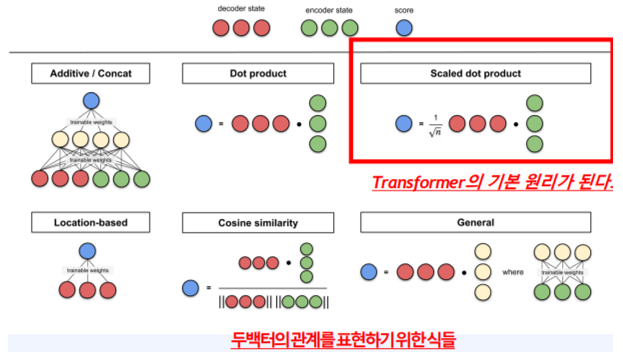
Vector 관계 표현식
되게 다양하다. 위에 다룬 예시는 Dot product 이지만 Scaled dot product가 Transformer의 기본 원리가 된다.
Attention의 비교
- Cross-Attention Vs Self-Attention
- Cross Attention
- 서로 다른 두 시퀀스(예: 소스 시퀀스와 타겟 시퀀스) 사이의 Attention
- 번역 작업에서 주로 사용
- Self Attention
- 동일한 시퀀스 내의 다른 위치들 사이에서 Attention을 적용
- Transformer 모델에서 각 단어가 다른 모든 단어와 관계를 학습할 수 있도록 함
- Cross Attention
- Soft-Attention Vs Hard-Attention
- Soft-Attention
- 모든 입력에 대해 가중치를 할당하며, 모든 값을 고려하여 출력을 생성
- 가중치는 연속적인 값
- Hard-Attention
- 특정 입력만 선택하여 출력을 생성
- 강화 학습을 사용하여 이산적인 선택
- 계산이 어려워 실제로는 많이 사용되지 않는다.
- Soft-Attention
- Global-Attention Vs Local-Attention
- Global-Attention
- 전체 입력 시퀀스를 고려하여 Attention을 계산
- 모든 위치에 대해 가중치를 계산
- Local-Attention
- 전체 시퀀스 대신 특정 윈도우(부분)에 대해서만 Attention을 계산
- 긴 시퀀스에 대해 더 효율적
- Global-Attention
정리
Attention Mechanism은 RNN이나 LSTM의 한계를 극복하여 긴 시퀀스 데이터를 효과적으로 처리할 수 있는 방법이다. 다양한 형태의 Attention을 통해 특정 문제에 맞게 조정할 수 있으며, Transformer와 같은 최신 모델에서도 핵심적인 역할을 하고 있다.

댓글