
서론에서 말했듯 LINE에서 활용하는 이벤트 기반 아키텍처의 개요는 아래와 같다.
🔥 오픈챗 서버에서는 메시지 전송과 메시지 리액션, 메시지 읽음 등과 같은 오픈챗 내 다양한 행위를 모두 이벤트로 간주하고 이벤트가 생성될 때마다 스토리지에 저장한 후 오픈챗에 참여하고 있는 모든 사용자에게 서버 푸시로 ‘새로운 이벤트가 생성됐으니 받아 가세요’라고 알린다. 서버 푸시를 받은 사용자(클라이언트)는 스토리지에 새로 들어온 이벤트를 페치(fetch) 이벤트 API로 받아가고 새 메시지 등을 화면에 추가하는 액션을 실행한다.
자 그럼 이제 핫 챗에서 급증하는 트래픽을 다룰 수 있는 LINE 만의 노하우를 알아보자.
🎮핫 챗에서 급증하는 트래픽을 다루는 방법
✅Case 1. fetch 이벤트 API 요청 급증
이 패턴을 이해하기 위해선 오픈챗 서버 구조를 더 자세히 들여다봐야 한다.
메시지를 전송하면 오픈챗 서버가 이를 스토리지에 저장하고 Kafka 이벤트를 전달한다. 오픈챗 서버 팀에서 ‘publish Server’라고 부르는 별도 서버에서 Kafka 이벤트를 소비해 새로운 이벤트가 생성됐다고 알리는 서버 푸시를 사용자에게 보낸다.
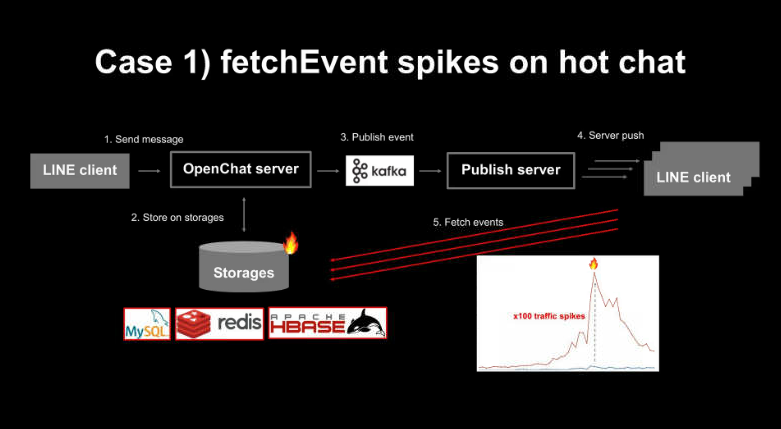
서론에서 언급한 사례처럼 사용자 5000명이 1초에 수십 개의 메시지를 주고받는 환경에서는 fetch event API 요청 수가 평소보다 급증하면서 특히 오픈챗 서버에서 사용하는 스토리지에 큰 부하가 발생한다. 아래 모니터링 지표는 핫 챗에서 fetch 이벤트 API가 급증하며 MySQL과 Redis 등의 스토리지에서 한 샤드에 전달되는 요청량이 3배 이상 급증하거나 스토리지 부하 때문에 오픈챗 서버에서 타임아웃이 발생하는 경우가 생긴다.

뿐만 아니라 핫 챗의 이벤트를 처리하는 Kafka의 한 파티션에 대량 이벤트가 생성되어 오프셋 랙(offset lag)이 증가하거나 핫 챗 요청을 처리하는 서버 그룹의 GC(Garbage Collect)와 CPU 사용량이 급증하는 것을 지표로 확인할 수 있다.
카프카 오프셋 랙(Offset Lag)_kafka Consumer Lag
카프카는 프로듀서와 컨슈머를 가지고 있다. 프로듀서는 토픽 내(파티션)에 데이터를 차곡차곡 넣는 역할을 한다. 이 파티션에 데이터가 하나씩 들어갈 때마다 각 데이터에는 오프셋이라는 숫자가 붙게 된다. 컨슈머는 파티션의 데이터를 하나씩 읽어오는 역할을 한다. 컨슈머가 데이터를 어디까지 읽었는지 확인하기 위해 오프셋을 남겨둔다. 만약 프로듀서가 데이터를 넣는 속도가 컨슈머가 가져가는 속도보다 빠른 경우, 이때 생기는 프로듀서가 마지막으로 넣은 오프셋과 컨슈머가 마지막으로 읽은 오프셋의 차이를 kafka Lag이라고 부른다.
GC(Garbage Collect)
프로그램을 개발하다 보면 유효하지 않은 메모리, 즉 가비지(Garbage)가 발생하게 된다. C를 사용하면 free()라는 함수를 통해 직접 메모리를 해제해주어야 하지만 Java나 Kotlin을 사용하면 개발자가 메모리를 직접 해제해 주는 일이 없다. JVM의 가비지 컬렉터가 불필요한 메모리를 알아서 정리해 준다. 메모리 활용에 유리한 방법일 것 같지만 개발자가 메모리가 언제 해제되는지 정확하게 알 수 없을뿐더러 GC가 동작하는 동안에는 다른 동작이 멈추기 때문에 오버헤드가 발생한다.

🧐WHY IT HAPPENED?
오픈챗 서버는 데이터를 저장하기 위해 MySQL과 Redis, HBASE, Kafka 등 다양한 스토리지를 사용하고 있으며, 챗 ID를 기반으로 샤딩(sharding)해서 데이터를 저장한다. 오픈챗 서비스가 성장해 더 많은 챗이 생성되면 샤드를 추가하는 방식으로 확장할 수 있는 구조이지만, 핫 챗은 하나의 오픈챗이므로 챗 ID를 기반으로 샤딩하는 구조에서는 하나의 핫 챗 안에서 발생하는 데이터를 더 이상 분산시킬 수 없다. 따라서 하나의 핫 챗에서 발생하는 모든 요청은 스토리지에서 하나의 샤드, 하나의 키로 몰리면서 부하가 집중된다.

😀Solution - Hot chat detection & throttling
가장 간단한 해결방법은 한 샤드로 집중되는 핫 챗의 부하를 줄이기 위해서 샤드를 추가해 전체 샤드 수를 늘리거나 샤드의 복제본(Replication) 수를 늘리는 방법을 고려해 볼 수 있다.
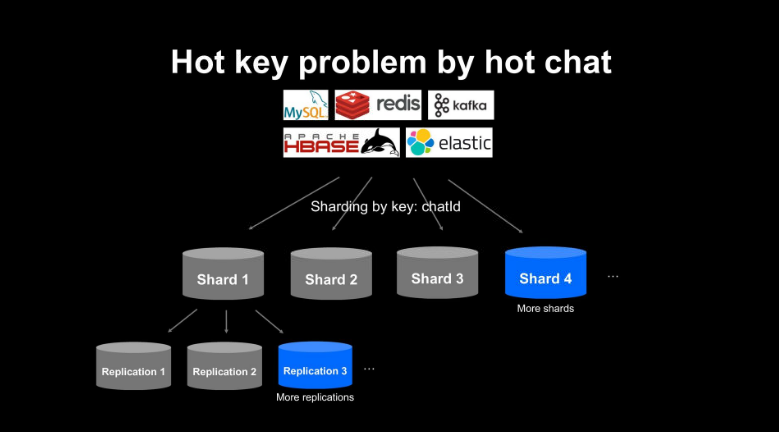
다만 핫 챗이 전체 오픈챗에서 차지하는 비중은 단 0.1% 미만이다. 언제 발생할지 모르는 극소수의 핫 챗을 위해 샤드를 추가하거나 전체 데이터의 애플리케이션 수를 늘리는 방법은 과한 대처방법이다. 문제 상황에서 필요한 직접적인 솔루션은 딱 핫 챗만 타깃으로 적용할 수 있는 해결방법이다.
따라서, 실시간으로 핫 챗을 탐지해서 핫 챗에서 발생하는 페치 이벤트 API 요청만 줄이는 결정을 하였다. 이 방법으로 핫 챗 때문에 하나의 샤드로 몰리는 부하만을 효과적으로 줄일 수 있다고 판단하였으며 이 방식을 핫 챗 감지 및 스로틀링(detection & Throttling)이라고 부르고 있다. 정확한 동작 과정은 아래와 같다.

우선 실시간으로 핫 챗을 감지할 수 있는 방법을 마련해야 한다. 이를 Kafka와 버킷(bucket)으로 구현했다. fetch 이벤트 API가 요청될 때마다 Kafka로 이벤트를 전송하고 퍼블리시 서버에서 이를 소비해 하나의 챗에 최근 몇 초 동안 몇 개의 fetch 이벤트 API가 요청됐는지 실시간으로 기록한다. 만약 fetch 이벤트 API 요청이 미리 설정해 둔 임계값(스토리지에 큰 부하를 주기 시작하는 요청 수) 보다 더 많이 들어온다면 이를 핫 챗으로 판단하고 해당 챗을 Redis에 잠시 저장한다.

이 과정을 코드로 보면, 챗 ID 별로 최근 몇 초 동안 몇 개의 페치 이벤트 API 요청이 들어왔는지를 기록할 수 있는 버킷을 준비하고, 페치 이벤트 API 요청마다 이 버킷에 기록하다가 임곗값을 넘으면 Redis에 해당 챗이 핫 챗임을 저장한다.
Cache<ChatId, Bucket> bucket;
public Completable process(kafka topic) {
boolean consume = bucket.get(chatId).tryConsume();
if(!consume) {
hotChatStorage.set(chatId, N seconds);
}
}퍼블리시 서버에서는 사용자에게 새로운 이벤트가 생성됐다고 알리는 서버 푸시를 보내기 전에 이 이벤트가 핫 챗으로 부터 나온 이벤트인지 Redis에서 확인한다.
만약 핫 챗이라면 서버 푸시를 확률적으로 쓰로틀링 해서 보내지 않는 방법으로 대량의 페치 이벤트 API요청이 발생하지 않도록 조절한다. 이 방법으로 핫 챗 때문에 발생하는 스토리지 부하만 타깃으로 잡고 줄일 수 있다.

핫 챗 스로틀링이 없는 경우 1초에 수십 개의 이벤트가 한 챗에서 생성되면 이벤트 생성마다 5천 개의 서버 푸시를 전송했고, 사용자는 5천 개의 페치 이벤트 API 요청을 호출했지만 적용 후 핫챗을 대상으로만 서버 푸시 개수를 조절할 수 있게 되었다. 사용자 입장에서는 하나의 서버 푸시만 받으면 새롭게 생성된 이벤트를 모두 받아갈 수 있기 때문에 1초에 수십 개의 이벤트가 발생하더라도 사용자에게 거의 영향을 주지 않고 핫 챗의 페치 이벤트 API 요청량만 효과적으로 줄일 수 있다.
여기서 핫 챗임을 탐지하는 기준치나 핫 챗일 때 서버 푸시 스로틀링을 몇 초간 어느 정도로 적용할지, 특정 챗에 스로틀링을 적용할지 등은 모두 LINE의 오픈 소스인 LINE Central Dogma만으로 서버 재기동 없이 동적으로 변경할 수 있도록 구현하였다. 따라서 갑자기 발생한 핫 챗에서 큰 부하가 발생해도 오픈챗 서버 팀에서 신속하게 대응할 수 있도록 하였다.

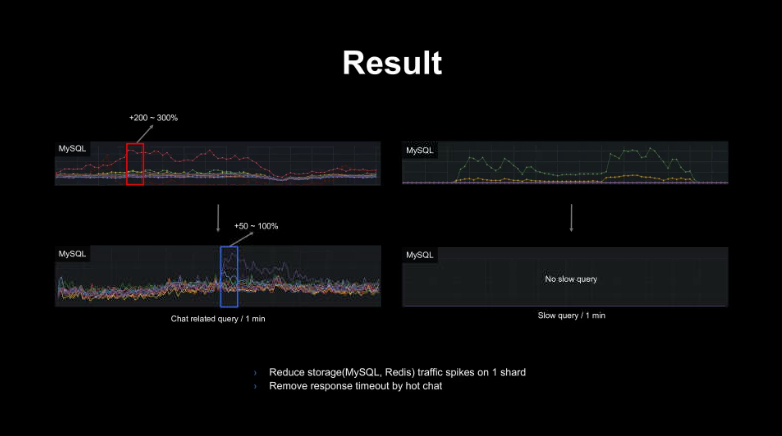
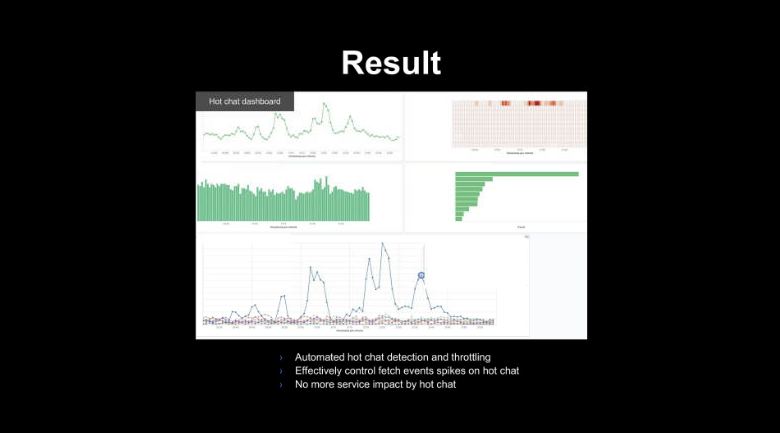
아래는 detection & Throttling 적용의 결과로 핫 챗으로 인한 스토리지 부하 등의 이슈를 효과적으로 대비할 수 있는 것을 볼 수 있다.
'기술블로그' 카테고리의 다른 글
| 우아한 형제들의 회원시스템 이벤트기반 아키텍처 구축하기 1 (0) | 2024.09.22 |
|---|---|
| LINE 오픈챗 서버가 100배 급증하는 트래픽을 다루는 방법 - 본론2 (0) | 2023.08.29 |
| LINE 오픈챗 서버가 100배 급증하는 트래픽을 다루는 방법 - 서론 (0) | 2023.08.01 |
| 네이버 메인 페이지의 트래픽 처리 - 마무리 (1) | 2023.07.13 |
| 네이버 메인 페이지의 트래픽 처리 - 본편 2 (0) | 2023.07.13 |

댓글